
In the evolving landscape of AI-driven chatbots, there’s a growing need for systems that provide more accurate and contextually relevant responses. Traditional chatbots rely heavily on pre-trained models, which can sometimes generate responses based on outdated information. However, RAG (Retrieval-Augmented Generation) chatbots are changing the game by combining the power of generative AI with real-time data retrieval. Let’s explore how RAG chatbots work, why they matter, and how you can build one yourself—plus how Agilno implemented a custom solution using Pinecone.
What is a RAG Chatbot?
At its core, a Retrieval-Augmented Generation (RAG) chatbot enhances the capabilities of generative AI by incorporating real-time, external knowledge into its responses. While standard chatbots rely on static knowledge embedded in the AI model (like GPT-3), RAG chatbots dynamically pull relevant data from external sources to generate more grounded, accurate answers. This makes them ideal for use cases that require up-to-date or specialized information that the model itself might not have.
Deep dive into our solution
At Agilno, we developed a custom solution for a client who needed their chatbot to handle detailed insurance information. The client provided documents about various insurance providers, including policies, age ranges, coverage details, and more. For example, users could query the chatbot with questions like:
“What is the age range for National Guardian Life Essential LTC policy?” To implement this, we followed these steps:
1. Document Chunking:
We split the large insurance documents into smaller, manageable pieces or “chunks” for efficient retrieval.
from transformers import AutoTokenizer
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
def chunk_text(text, max_length=512):
tokens = tokenizer.encode(text, add_special_tokens=False)
# Split into chunks
return [tokens[i:i + max_length] for i in range(0, len(tokens), max_length)]
2. Embedding and Storing Chunks in Pinecone:
We converted these chunks into vector embeddings using Hugging Face’s transformers library and stored them in Pinecone, enabling fast similarity searches when a query is made.
import pinecone
from transformers import AutoModel, AutoTokenizer
import os
import torch
# Initialize Pinecone using environment variable for API key
pc = pinecone.Pinecone(api_key=os.environ['PINECONE_API_KEY'])
# Set index name
index_name = 'your_index_name'
# Connect to Pinecone index
pc_index = pc.Index(index_name)
# Load tokenizer and model for embeddings
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
# Example text chunks
text_chunks = ["National Guardian Life Essential LTC policy",
"Age range: 40-75",
"Coverage details: ..."]
# Convert to embeddings and store in Pinecone
for chunk in text_chunks:
# Tokenize and encode text
inputs = tokenizer(chunk, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# Extract sentence embeddings (averaging over token embeddings)
embedding = outputs.last_hidden_state.mean(dim=1).numpy()
# Upsert embeddings to Pinecone
pc_index.upsert(vectors=[(chunk, embedding)])
3. Querying Pinecone:
When a user asks a question, the chatbot retrieves the most relevant chunks from Pinecone.
def query_pinecone(query):
# Convert query to embedding
query_embedding = model.encode(query)
# Query Pinecone for similar chunks
results = pc_index.query(query_embedding, top_k=3)
return results
# Example query
user_query = "What is the age range for National Guardian Life Essential LTC policy?"
relevant_chunks = query_pinecone(user_query)
4. Generating a Response:
Once relevant chunks are retrieved, the chatbot uses a language model to generate a response based on the user query and the retrieved information.
# Initialize language model pipeline
generator = pipeline('text-generation', model='EleutherAI/gpt-neo-2.7B')
def generate_response(query, retrieved_chunks):
context = " ".join(retrieved_chunks) # Combine retrieved text
response = generator(f"{query} {context}", max_length=200, do_sample=True, temperature=0.7)
return response[0]['generated_text']
# Generate response based on the query and retrieved chunks
response = generate_response(user_query, relevant_chunks)
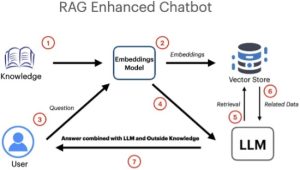
How Does a RAG Chatbot Work?
A RAG chatbot integrates two key processes:
- Retrieval Phase: The chatbot first queries a database or external knowledge repository (in our case, Pinecone) for relevant information based on the user’s input. (We used Pinecone to store insurance policy chunks as vector embeddings and retrieve the most relevant content based on similarity search).
- Generation Phase: Once relevant data is retrieved, the chatbot uses a language generation model (like GPT-Neo) to craft a response. This approach ensures that the chatbot’s responses are factually grounded and context-aware.
Why Should You Use a RAG Chatbot?
There are several advantages of using a RAG chatbot over traditional generative models:
- Improved Accuracy: Since the chatbot pulls information from reliable, up-to-date sources, it produces more accurate and factually correct responses.
- Domain-Specific Expertise: You can customize a RAG chatbot to fetch data from industry-specific sources, allowing it to handle highly specialized queries.
- Scalability: By simply switching the knowledge base it queries, you can create a chatbot for a new domain without retraining the underlying language model.
Challenges of RAG Chatbots
While RAG chatbots offer significant advantages, they are not without challenges:
- Latency: Fetching data from an external source and then generating a response can introduce some delay. Optimizing retrieval and generation speed is crucial.
- Relevance: Ensuring that the retrieved data is contextually relevant to the user query is an ongoing challenge, especially with large datasets.
- Knowledge Management: The knowledge base must be regularly updated to remain accurate, and maintaining and re-indexing data can be labor-intensive.
Real-World Applications
RAG chatbots have already made a significant impact across industries:
- Customer Support: Chatbots can pull from internal documents to answer customer queries about products, troubleshooting, and order statuses.
- Education and Research: They assist in answering highly specific, domain-focused questions using academic papers and research documents as sources.
- Internal Knowledge Bases: Large organizations use RAG chatbots to provide employees with quick access to internal documentation, policies, and procedures.
Conclusion
RAG chatbots represent a powerful step forward in the chatbot space. By combining the creative power of generative AI with the precision of real-time data retrieval, they open up new possibilities in customer service, knowledge management, and beyond. At Agilno, we’ve successfully implemented a RAG-like approach using Pinecone, helping our clients enhance their chatbot capabilities with custom document-based knowledge about insurance policies.
If you’re looking to develop a smarter chatbot, RAG—and our unique expertise—can help you get there.

